
Substack Zombie Wave
The Dead Internet? Not a theory, it's right here, right now.

Let’s have another look at what was first mentioned inApril 8th’s Begone, Beneficial Botnet, and which got a closer look in April 30th’s About That Beneficial Botnet. The big picture here is that I simply removed the foreign policy articles that were getting boosted and the botnet wandered off. This does not seem to be about me personally, it appears to be a systemic thing. It should be evaluated further, but that requires both time and some code. This is another little milestone on that path.
Attention Conservation Notice:
Zombie hunting, some GraphCraft here. You know, metrics nerd stuff. You either eagerly skipped ahead, or you don’t really belong here in the first place.
Arrival:
Here’s my audience on March 11th.


And here it is on April 8th, after I politely showed the botnet out.


See how the follower curve flattened out with the botnet sent packing? The mystery here is the shape of the follower curve before March. That growth is awfully linear …
Analysis:
So what do we DO about this? Not so much about the followers, at least not yet, but Substack permits export of one’s subscribers, their email and their date of arrival. A normal pattern would involve some articles that garner new audience, and many that are not at all special. Maltego makes it easy to see this.

And it’s easy to find out which days mattered. Eight of the top ten events are during the window where the botnet was really active.

Let’s take a look at the flow through time.
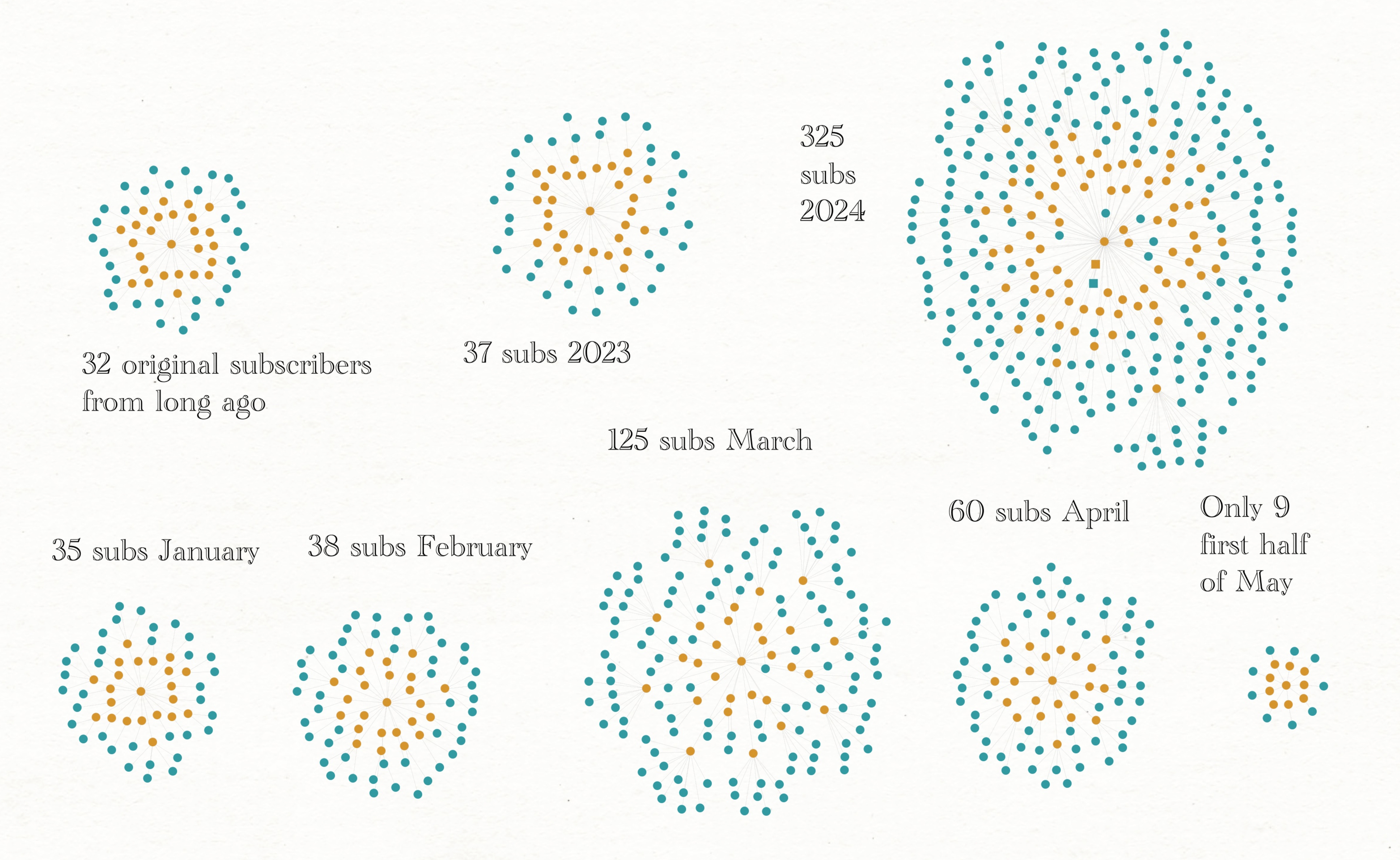
During 2024 I added about one new sub a day, but this is not accurate - because there was an enormous influx that began with MIOS: Iran’s PressTV. Even so, I don’t care enough to untangle that. January and February were just more than one a day, then March quadruples?
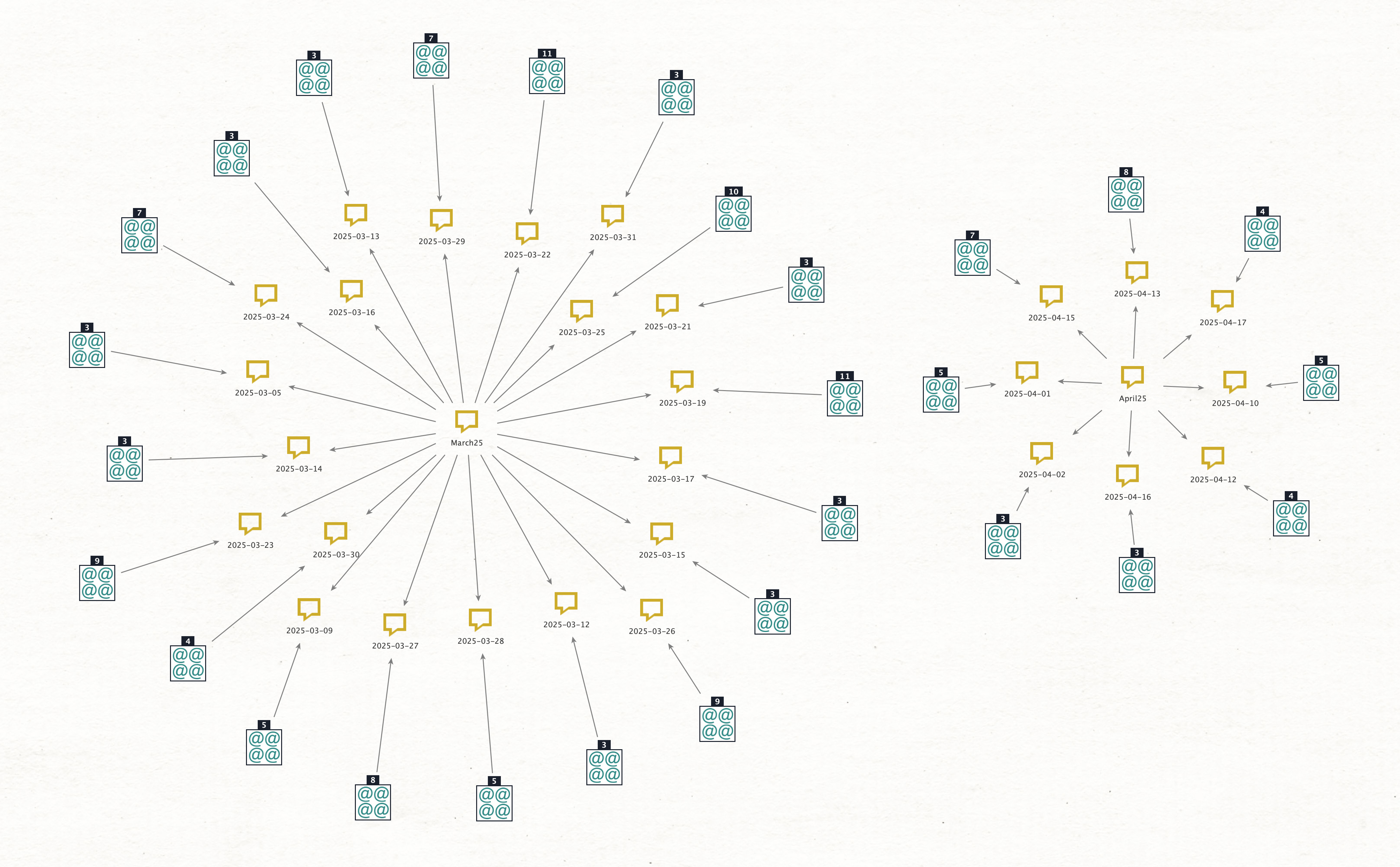
March and April arrivals, just for days with three or more, because I’m too lazy to hand edit all the singles/doubles for privacy. Expand it, look at the clusters of dates. A machine on the move.

There’s not anything obvious in the domains used for subscriber email, not in the whole set, nor in the March/April 2025. Their distributions are the same - mostly people use Gmail, you can pick out the old folks with Hotmail or Yahoo.
API:
I decided to see what I could do to automatically profile things here, and look at what I found from March 2nd. Is this the engine behind the botnet? It’s been around for a while, but it’s maturing.

And Substack 2025 is a lot like Twitter 2009 - light, fast, not a lot of obstacles. This is a “FOAF” graph - I started with my account, got the list of what my subscribers are reading, and large names here means more subs. This is a very different environment from Twitter though, one where I’m going to have to make allowances for preferential attachment. Unlike Twitter, where I had a list of 1,300 accounts in an ArangoDB set called “useless”, the big accounts here are going to remain relevant.

I am a user of APIs, not a creator of, but in this case I see a not terribly complex pool of Python code, a single developer, and it’s missing some things that I would really like to have. So maybe I am about to rig up a PyCharm to Claude link and wade in swinging.
Conclusion:
If you look at the options for filtering in the Substack interface it’s bean counter heaven - everything you could ever want to know about your subscribers, it’s there. What is utterly lacking is any information about their relationships to each other. What I expect to see here is the current free for all giving way to “Oauth required”, just like Twitter did. As long as the rate limits are sensible that’ll be fine.
It’s been a long time since I had a social network I could program, and even longer since I could do it w/o grinding my teeth while waiting for results. This is going to be … fun.