
Pencil, Paper & Terminal
Learning before the web existed.

Way back when, I attended Iowa State University, where I dodged using a beast like the one seen below by just a single semester. We learned in what would be seen as an archaic way today - sit down with a pencil, some paper, sketch out what you wanted to do, then sit at a terminal and tap away at the keys until you had something that worked.
The more the world changes, the more valuable this archaic education becomes. We’re going to lose much of this to AI, and those that retain the discipline will end up in charge.

Attention Conservation Notice:
Old man, who seems to want a caretaker job in a computer museum, waxes poetical about the good old days when a VAX MIP literally meant what your VAX 11/780 could do in a little less than a microfortnight.
What Matters:
What we were taught back then was a lot of discrete mathematics. Everything was set theory, combinatorics and probability, algorithm analysis, and the like. Data structures covered things like queues, stacks, linked lists - all things that are now abstracted by endless value added packages. Databases today are just API calls, back then you learned about B+ trees in an intimate, hands on fashion.
We programmed exclusively in declarative languages - Pascal at first, then C in some later classes. I was precocious so I managed a little time in a functional programming environment (LISP), and THE buzzword duo of the 1980s was “object oriented”. I tried Smalltalk, but Actor worked best on the equipment available to me in those years.
Database design was grounded in entity-relationship diagrams. Rumbaugh’s Object Modeling Technique was a revelation I pursued on my own.
Last weekend I started with a clean sheet in my graph paper notebook and began sketching out an object model for Substack, with the intention of mapping the JSON returned by the API into an ArangoDB database.

That’s a tiny little thing, but it’ll grow as I start working with the data. There are relationships within Substack that are not explicitly exposed by the API, those will need to be added to the graph. Some of them are visible, but stateless. We’ll need the date they were first noticed, and the date they were last observed. That mattered more for Twitter than it will here, but it’s still going to be useful, when it comes to network growth dynamics.
Enterprise Scale:
One of the things I do, that my peers do not, is build industrial strength solutions. Once upon a time I was responsible for ISPs continuing to run in the face of disaster, and I’ve never lost that mindset. Being up despite insults and coming back quickly from catastrophe seem pedestrian to me, but it impresses my fellows.
Below is a dated example - the Twitter streaming service. A user looking at it sees a timeline, maybe they favorite some tweets, put accounts on lists. How I saw it was via eighty OAuth’d API accounts, all streaming specific tweet content to Elasticsearch indices. They incidentally caught all the involved user profile objects while doing this, and those were dropped into Redis. Other worker threads would take those objects from Redis and see if the ArangoDB user profile store needed to be updated. If there were specific accounts receiving social network analysis, their friends/followers would get pulled, and any that were not in ArangoDB would get added to the Redis queue.
Twitter has a “leaky bucket” scheme for API access. It refills to the max every fifteen minutes, but it won’t overfill. Having all eighty accounts go at once created a huge spike that would overload the systems. Even dividing streaming and lookup into two separate machines didn’t solve that. What worked was setting up cron jobs. Once every minute five accounts would begin waiting between one a thirty seconds to start their work. This was not perfect, but it was easily coded, and it turned those spikes into a steady flow of little bumps that passed unnoticed.

This was the hardware we had when this was current, back in 2020 - 2021. Two workstations in my house were being turned down, three rack mounts were taking their place. One machine was primarily for Twitter, one for Open Semantic Search, and an old dog that got a VMware ESXi license for experiments. The OSS box was idle a lot of the time, so it reached out over the network to lend a hand on activity on the Twitter machine. Later they all evolved to running the Proxmox cloud environment.

Current:
The last server for OSS was turned down in January. All I have now are the DeskNet systems, sitting right behind me. Opti is maxed out at 32GB and has been Proxmox since inception. Titan, the little HP EliteDesk G5, got put on Proxmox duty a while back. Titan is 32GB but could be 64GB if needed. Neither of them have GPUs and this is fine. I spent a couple years lusting after a GPU more potent than the GTX 1060 I had, but now anything AI related is going to be API calls.
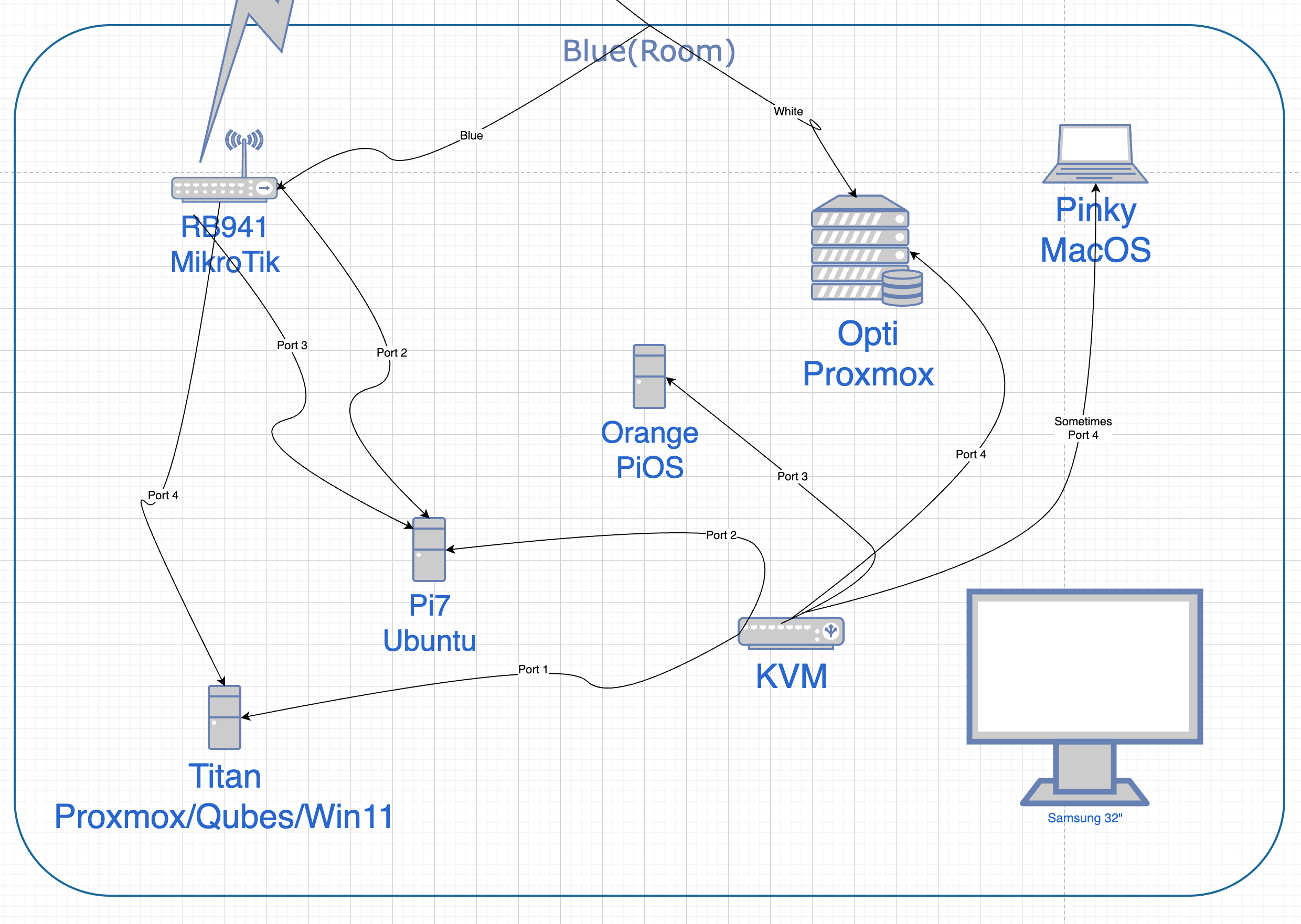
Apple silicon, in general, is much more capable than AMD64 systems, but I’ve never been able to take advantage of that. Anything I do has to be able to migrate from Apple to a Proxmox VM - when employing this enterprise suitability as a requirement, Macs are just lightweight browser/terminal systems.
Conclusion:
We are indeed at an inflection point with AI. I didn’t get how imminent it is or what it meant until I started following Matthew Berman - his piece on Sam Altman’s Predictions has given me the direction I was previously lacking.
The very nature of employment is about to change, but in timeframes of weeks and quarters, not the years and decades of the Industrial Revolution. Publicly I am working on Shall We Play A Game? and Reviving Disinfodrome. Both efforts have a strong AI component to them. For every one that is known, there are two that remain private. I only have time to do two of the six and its not clear which will progress most rapidly. Friends will inherit the things I set in motion that I don’t have time to do myself.
I’ve been looking back at my successes since the turn of the century as this unfolds:
Wireless ISP taken to first round funding.
Grant winning renewable ammonia R&D.
Congressional policy intel effort that reached 23% of all staff at its peak.
Large scale Twitter analytics service.
Large scale document handling for research & reporting.
Each of these experiences has features that matter, but the one that resonates the most is the one in the middle - Progressive Congress News. The ability to get groups of humans to pool cognitive surplus might seem to be a counterintuitive thing in the face of rising artificial intelligence, but I’m going to say that thing some of you have grown weary of hearing.
Network threats will often best a even a well run, self aware hierarchy.