
Gemini 3
Google's LLM launches HARD.

Google’s Gemini 3 LLM appeared today and it very much shares a vibe with the other Gemini 3 - the first time two Americans went into space together.
LLMs have been going at it like a NASCAR pack entering the final lap, but today Google put the hammer down and just ran away from the crowd. This is the best I could manage with the ARC Prize scatter plot. The green at the bottom is the old Gemini 2.5, the top center green is Gemini 3 Pro, and the far and away leader at the upper right is Gemini 3 Deep Think.
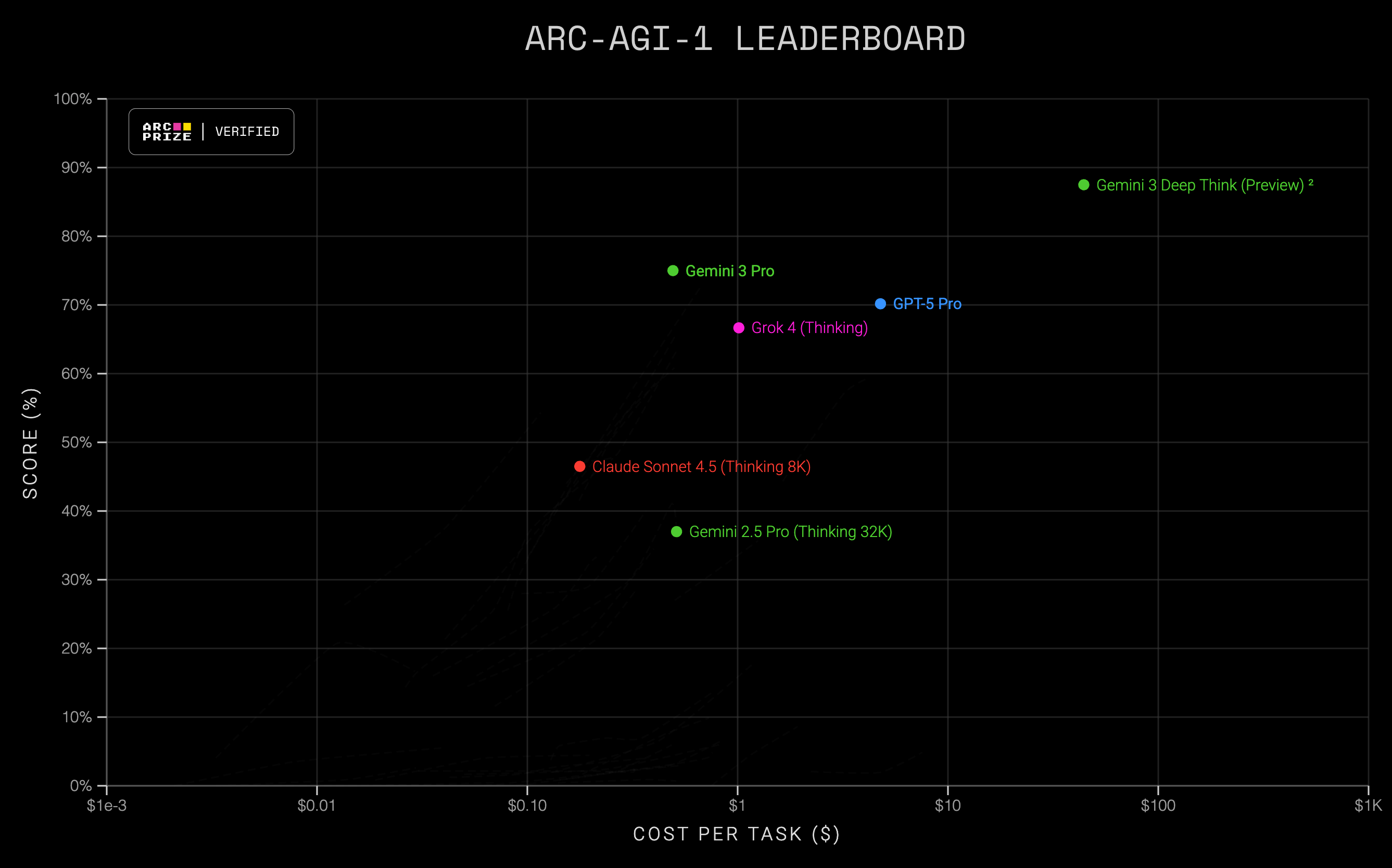
Here’s an ensemble of benchmarks. Instead of prevailing by percentage points, Gemini 3 comes out on top by multiples.
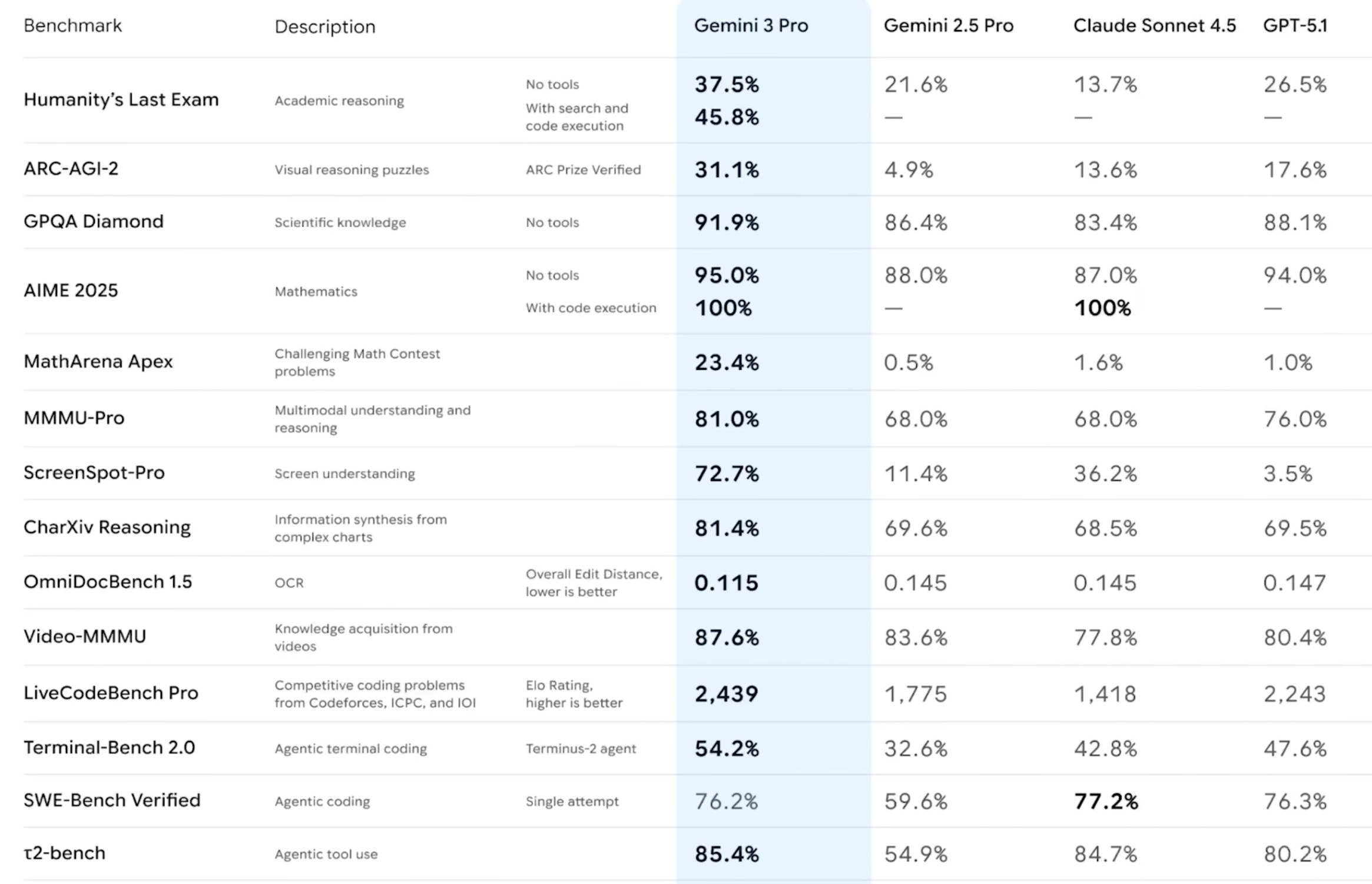
The best take on what this all means is of course Nate B. Jones.
Experimentation:
Just a couple days have passed since I could wake up and not have to mess around with faulty GPU hardware or archival drives in roles they were never meant to have. I employed Comet/Perplexity, instead of my usual Chrome/ChatGPT, and made good progress on vLLM. I already have it providing an OpenAI compatible API, but I want it to do Anthropic, too, so I can keep the ball rolling with Claude Code when I’m in the mood to program.
We have a specification and prompts for our MVP (minimum viable product) app. Today I pulled a copy of it from Github after the design team said “go” and the demo built in one shot using bare Claude Code in a terminal window. I started the iOS emulator when I was done, clicked around a bit, and showed some screen shots.
During the last thirty days I have for the first time laid hands on …
Proxmox clustering
Proxmox GPU passthrough
CloudInit
Microk8s
HuggingFace models
vLLM
Anthropic/OpenAI API proxy
The HuggingFace download utility is, objectively speaking, a total piece of shit I’d be embarrassed to sign my name to, but as I described in Hugging Face Downloads, it eventually did what I wanted. Six months ago the obstacles I encountered would have led me to abandon the effort, not being able to predict when, or even if it would work.
The rest of these things are more tractable problems, but we’re still talking the sort of thing that would have burned up … weeks of my time, for each, as recently as six months ago.
Conclusion:
You might be reading this because I am ahead of you, but do not get the idea that I’m good at this stuff (yet). At the rate I’m moving I expect that by year end I will finally be able to accurately describe what I don’t know. If I’m really feeling it I might even be able to estimate how long it will take me to finish climbing the learning curve.
Recognizing that I now manage to qualify as competent in … a third to half of what I need to do the job I have taken on, I’m still OK with this. Because with ChatGPT explaining the basics and Claude writing some decent code after just being given hints, things that used to take a quarter now get done in a weekend. And I’ve only touched Claude Code’s extensibility in a cursory fashion, despite knowing that it’s truly amazing. That’s what is up next for Claude Camp.
What matters here is … Nate has used the same word … judgment. There are things where I can easily spot sense/nonsense - Linux, Python, distributed systems, the things I mastered doing by hand before LLMs existed. I have gone down some disappointing rabbit holes, but I back out, recognizing the contours of those problems already familiar to me, appearing again in what I just experienced. I am starting to call bullshit on everything that looks the slightest bit off to me, and calling again when the LLM comes up with improvements.
It’s weird to be here, with a whole career involving deterministic systems behind me, and sixty rushing at me, getting used to working with these squishy, statistical creatures. And I do mean “working”, not “using” - this literally does feel a bit like a new organization and new team mates.
So … where do you think we are on this curve?
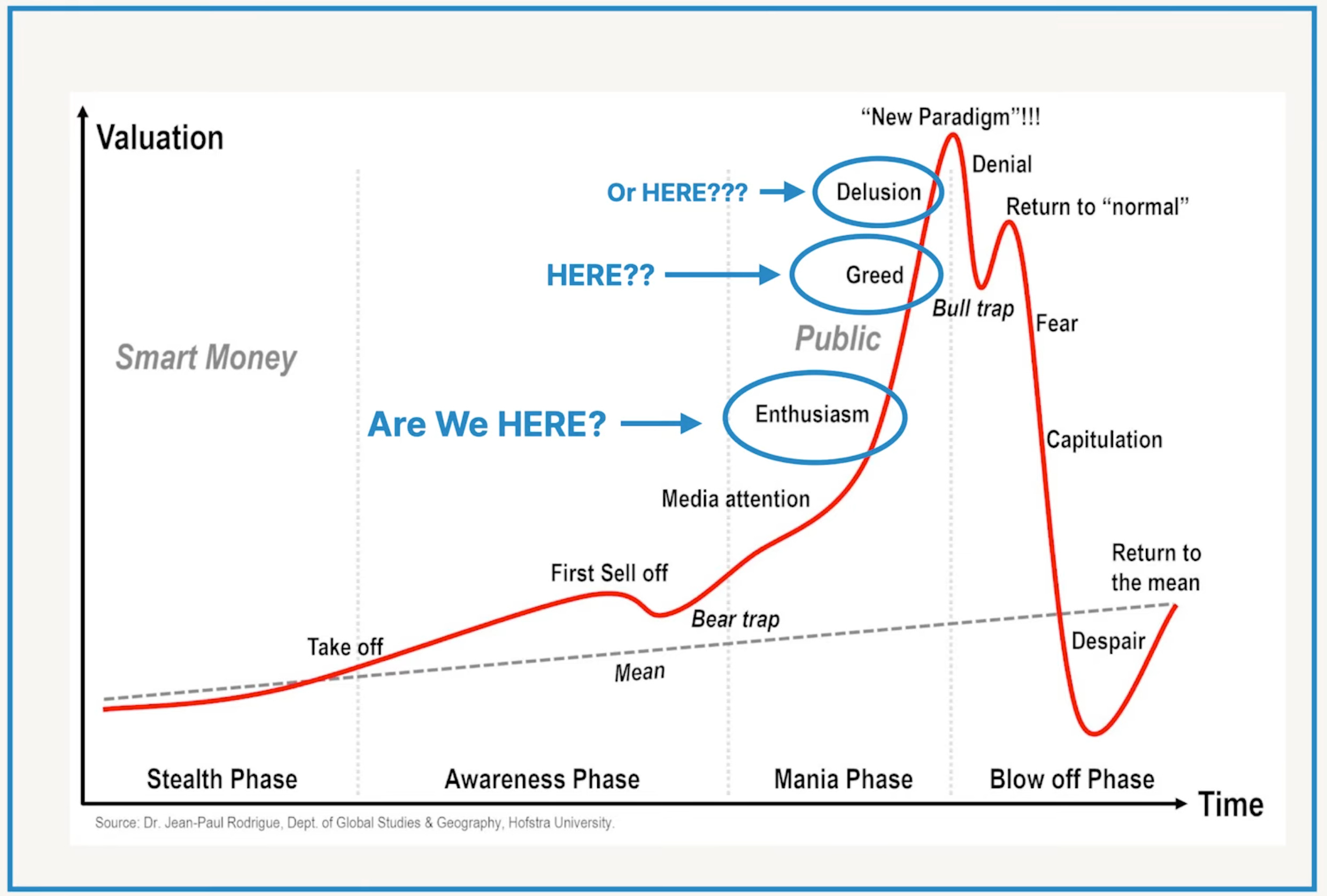
Those benchmark comparisons are wild, Gemini 3 Deep Think really does stand out. Your point about judgement is what maters most, the abilty to recognize when you're going down a rabbit hole is crucial. Tasks that used to take weeks now getting done in weekends is the kind of compresion we're seeing across the board.