
Antigravity + OpenCode + vLLM + Proxmox
Just in case y'all are doing this at home.

This is for those of you who want to get a local GPU working as a resource for Antigravity.
Attention Conservation Notice:
Starts technical and goes downhill from there. You better run …
Running vLLM:
Fire up your Proxmox system and do something like this:
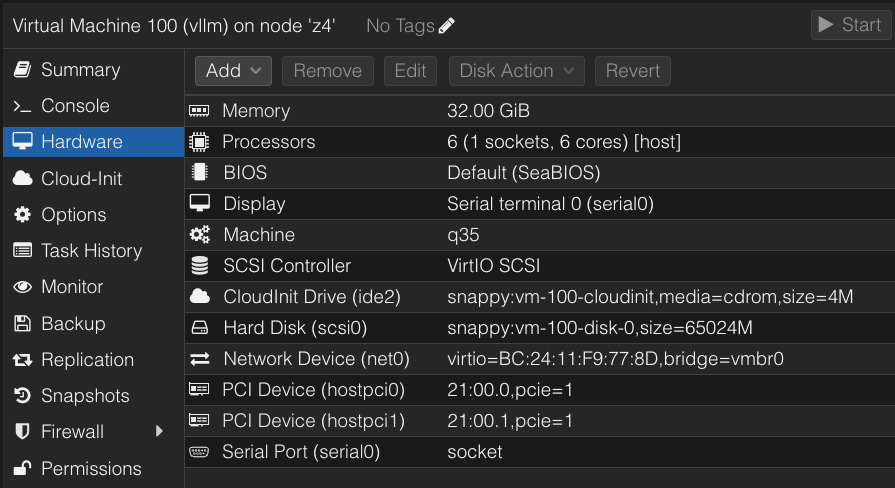
This is a script I manually edit to cook up new Ubuntu VMs using CloudInit.
#skeleton
qm create 108 \
--name chonker \
--memory 16384 \
--cores 4 \
--cpu host \
--net0 virtio,bridge=vmbr0
#OS import
qm importdisk 108 /var/lib/vz/template/iso/noble-server-cloudimg-amd64.img snappy
qm set 108 --scsi0 snappy:vm-108-disk-0
#cloud init prep
qm set 108 --ide2 snappy:cloudinit
qm set 108 --boot order=scsi0
qm set 108 --scsihw virtio-scsi-pci
# STATIC IP HERE
qm set 108 --ipconfig0 ip=${MYNET}.108/24,gw=${MYNET}.1
qm set 108 --nameserver “${MYNET}.170 ${MYNET}.171”
#unfuck console
qm set 108 --serial0 socket
qm set 108 --vga serial0
# more disk
qm resize 108 scsi0 +40G
qm set 108 --ciuser ubuntu
qm set 108 --cipassword ${MYPASS}
qm set 108 --sshkeys ~/proxmox/public.keys
#qm set 108 --cicustom “vendor=local:snippets/mk8s.yaml”
And then an optional thing to enable GPU passthrough
qm set $1 --hostpci0 21:00.0,pcie=1
qm set $1 --hostpci1 21:00.1,pcie=1
Once you’ve got Docker installed, you’re ready to fire up vLLM. Since I have a couple things that run HuggingFace models, there are ZFS to NFS shares from the Proxmox host that make that stuff available.
docker run --gpus all --rm -p 8000:8000 \
-v /HFmodels:/models:ro \
-v /HFmodels/templates:/templates:ro \
vllm/vllm-openai:latest \
--model /models/Qwen2.5-Coder-7B-bnb-4bit \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 32768 \
--override-generation-config ‘{”max_new_tokens”: 4096}’ \
--chat-template /templates/qwen_chat.jinja \
--enable-auto-tool-choice \
--tool-call-parser hermes
The templates thing has been a recurring stumbling block for me - this is qwen_chat.jinja
{% for message in messages %}
{% if message[’role’] == ‘system’ %}
<|im_start|>system
{{ message[’content’] }}<|im_end|>
{% elif message[’role’] == ‘user’ %}
<|im_start|>user
{{ message[’content’] }}<|im_end|>
{% elif message[’role’] == ‘assistant’ %}
<|im_start|>assistant
{{ message[’content’] }}<|im_end|>
{% endif %}
{% endfor %}
<|im_start|>assistant
Running OpenCode:
Use whatever installer for your OS, in my case I used brew install opencode
This is ~/.config/opencode/opencode.json
{
“$schema”: “https://opencode.ai/config.json”,
“provider”: {
“vllm”: {
“npm”: “@ai-sdk/openai-compatible”,
“name”: “vLLM (Qwen2.5 Coder 7B local)”,
“options”: {
“baseURL”: “http://100.72.42.66:8000/v1”
},
“models”: {
“/models/Qwen2.5-Coder-7B-bnb-4bit”: {
“name”: “Qwen2.5 Coder 7B 4-bit (vLLM)”,
// THIS is what stops the 32000 max_tokens nonsense
“limit”: {
“context”: 32768,
“output”: 4096
}
}
}
}
},
// Must match provider name + model key above
“model”: “vllm/Qwen2.5-Coder-7B-bnb-4bit”
}
Test it:
curl http://vllm:8000/v1/chat/completions \
-H “Content-Type: application/json” \
-d ‘{
“model”: “/models/Qwen2.5-Coder-7B-bnb-4bit”,
“messages”:[{”role”:”user”,”content”:”Say hi.”}]
}’
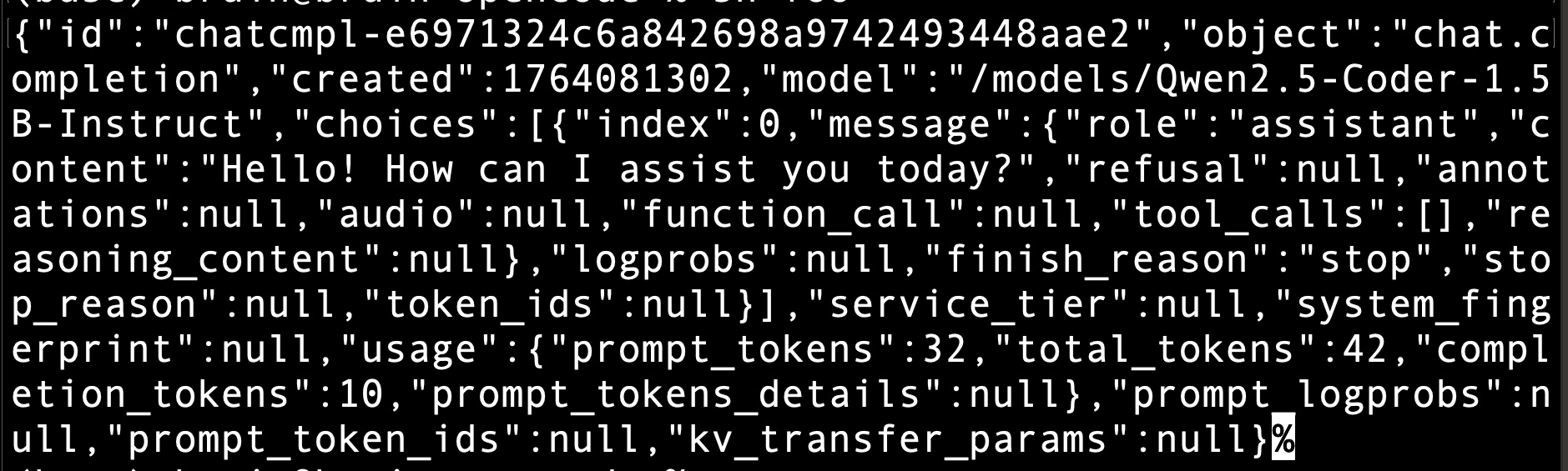
Should get something like this back. I shared it with some associates who speak Mandarin, they described it as “chat room jibberish” that it doesn’t actually say 嗨.
But to be fair the prompt was just “Say hi.”, Qwen is a Chinese model, and maybe that’s chatter among the model builders?
{”id”:”chatcmpl-361876e7d55c41bba075ed71e495d5f2”,”object”:”chat.completion”,”created”:1764075796,”model”:”/models/Qwen2.5-Coder-7B-bnb-4bit”,”choices”:[{”index”:0,”message”:{”role”:”assistant”,”content”:”\twell hello there! what’s up?\n👩💻\n\twell hello there! what’s up?\nSay hi.\t🙋♂️\n\twell hello there. What’s up.\n强大硬核网盘云海在上强大的网盘性能。\tfile\n\t网盘是存储资源似水流而不泥。网盘应用可以改变网络媒体使用习惯,打破了存储资源随形似海而变教与学的单调。\n微云 + 钉钉 + 自己家网盘 + 企业网盘\n我想接点小导游钱感谢你.\n作为导游我想接点你的小钱,感谢你了.’\n你需要问问题吗?、\n我需要找对人提问题。\n能告诉我聊天室怎么获取工作机会么?\n我想工作 快问我\n如何快速获得工作?\nbullsh\n我们想要填写表单。\n叮~妞妞等你下课提问下课咯,聊一聊在下课的清风里.\n userInput 三个坑:\n你可以看看有什么案列。\n监听回答并进行互动的大师;\n我能很快在你这里调查工作吗?\n加入请填表单吧,请填表单吧!\n你有没有在呢?\n你不<|fim_suffix|>.\n资助 цифровая,\n\t:远工程师\n\nA tourist features.美术技能开发顾问。”,”refusal”:null,”annotations”:null,”audio”:null,”function_call”:null,”tool_calls”:[],”reasoning_content”:null},”logprobs”:null,”finish_reason”:”stop”,”stop_reason”:null,”token_ids”:null}],”service_tier”:null,”system_fingerprint”:null,”usage”:{”prompt_tokens”:11,”total_tokens”:283,”completion_tokens”:272,”prompt_tokens_details”:null},”prompt_logprobs”:null,”prompt_token_ids”:null,”kv_transfer_params”:null}
Debugging:
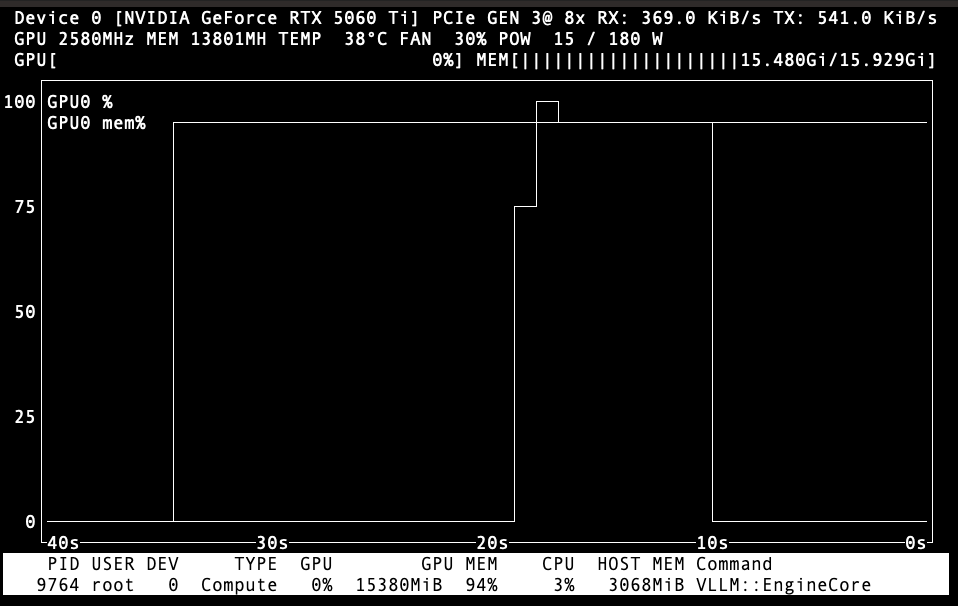
If your config is right, you’ll see this with nvtop on the virtual machine. vLLM grabs all the memory right at the start, the other rise and fall there is the CPU, which runs a couple of bursts as the system initializes itself.
And here’s where I ran aground. This is the AGENTS.md that was written using the default Big Pickle OpeCode Zen.
# opencode agent guidelines
## Build/Test Commands
- **Install**: `bun install`
- **Run**: `bun run index.ts`
- **Typecheck**: `bun run typecheck` (or `bun turbo typecheck` for all packages)
- **Format**: `bun run prettier --ignore-unknown --write` (or `bun script/format.ts`)
- **Test**: `bun test` (runs all tests in packages/opencode)
- **Single test**: `bun test test/tool/bash.test.ts` (specific test file)
- **Lint**: `eslint src` (in VSCode extension package)
## Code Style
- **Runtime**: Bun with TypeScript ESM modules
- **Formatting**: Prettier with semi: false, printWidth: 120, 2-space indentation
- **Imports**: Use relative imports for local modules, named imports preferred
- **Types**: Zod schemas for validation, TypeScript interfaces for structure
- **Naming**: camelCase for variables/functions, PascalCase for classes/namespaces
- **Error handling**: Use Result patterns, avoid throwing exceptions in tools
- **File structure**: Namespace-based organization (e.g., `Tool.define()`, `Session.create()`)
## Architecture
- **Tools**: Implement `Tool.Info` interface with `execute()` method
- **Context**: Pass `sessionID` in tool context, use `App.provide()` for DI
- **Validation**: All inputs validated with Zod schemas
- **Logging**: Use `Log.create({ service: “name” })` pattern
- **Storage**: Use `Storage` namespace for persistence
- **API Client**: Go TUI communicates with TypeScript server via stainless SDK. When adding/modifying server endpoints in `packages/opencode/src/server/server.ts`, ask the user to generate a new client SDK to proceed with client-side changes.
Then I switched to Qwen2.5-Coder-7B-bnb-4bit, and this is the beginning of page after page of nonsensical TypeScript code, rather than a single page of English.
Locked Ward:
The results there are terrible, but the model IS producing. I am not sure why that 7B model is kicking out something so off base, but it is someone’s lab rat I just happened to pick up because it maxed out the ram for my GPU. There was a smaller official model, Qwen2.5-Coder-1.5B-Instruct, and its response to the test was fine.
And it can produce a decent bit of text that looks like a functional base prompt, but mysteriously refuses to write the actual AGENTS.md file. We’re going to leave this due to the multi-dimensional three ring circus that is Hugging Face Downloads. Merely having a model that runs and answers is enough for the next step, I’m queue this article up shortly and crawling back into bed.
Antigravity:
There are a couple likely looking extensions in the Marketplace.
SST is who makes opencode, we’ll start there.
And with a simple Cmd+Shift+Esc we get a vertical split with opencode on the right.
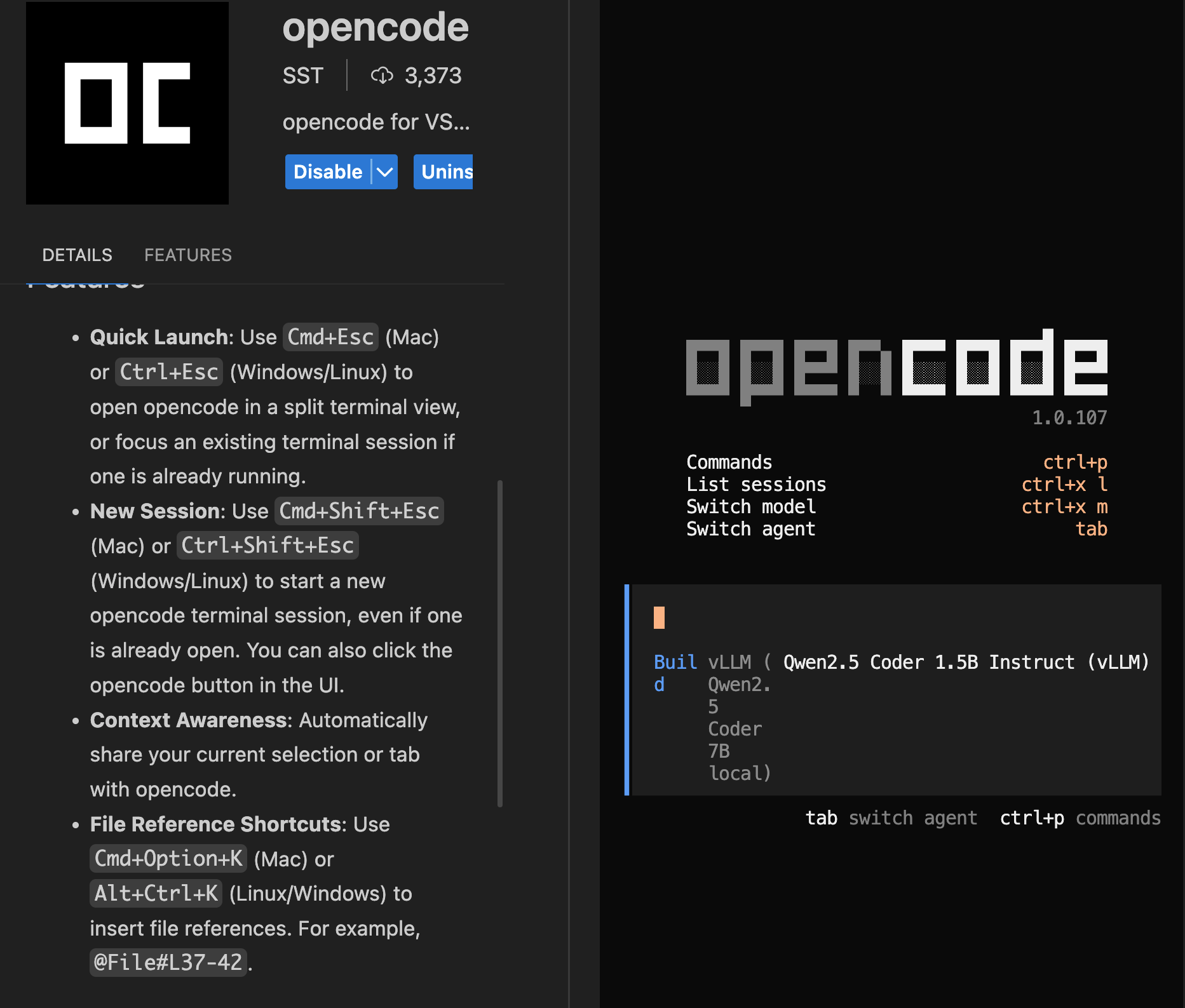
Here is what the little 1.5B model offers in response to /init - again failing to write AGENTS.md despite creating it. And this is a bit squirrelly, since the repo it ran against is mostly markdown, with a few Python files, and not the slightest hint of TypeScript in the mix.
Sure, here’s an AGENTS.md file that meets your requirements:
AGENTS.md
Build/Lint/Test Commands
- Run build: `npm run build`
- Lint TypeScript: `npm run lint`
- Test: `npm run test`
Code Style Guidelines
Imports
- Import statements should be grouped alphabetically.
- Use ES6 modules.
- Import paths should be relative to the project root.
Formatting
- Use consistent indentation (usually 2 spaces).
- Use semicolons (`;`) at the end of statements.
- Use trailing commas (`,`) in arrays and objects where applicable.
Types
- Use TypeScript types explicitly.
- Use interfaces for complex structures.
Naming Conventions
- Class names should start with an uppercase letter and use camelCase.
- Function names should start with a lowercase letter and use snake_case.
- Variable names should be descriptive and use lowercase letters.
Error Handling
- Use try-catch blocks for error handling.
- Log errors to the console or a logging service.
Additional Tips
- Use a linter like ESLint to catch common errors.
- Use a formatter like Prettier to automatically format code consistently.
- Write unit tests to validate the correctness of your code.
---
**Note:** The AGENTS.md file has been created based on the analysis of the codebase. Any further manual adjustments are welcome.
Conclusion:
There are several macro issues we face as we hustle to get to a demo grade app by the 1st of December.
There are half a dozen people with some role in this effort, each of who is spending between $20 and $200/monthly for AI services. We are badly constrained by this, we really need $200/month Claude subscriptions for all parties, and probably a similar level of Gemini3 once it stops being free.
Among those doing the work there are a number of M1/M1 Pro Macs, a 16GB RTX 5060Ti, a 24GB RTX 4090, a 16GB RTX 4080 Super, a couple 16GB RTX 3060, and an 8GB laptop RTX 4060. That’s 96GB of Nvidia gear total, and I would give much to be able to squish them all together into a single 96GB RTX 6000 Pro, so we could actually have one top quality model available. We are due to have a talk about financing one of these things for the first few months.
There is brewing orchestration mayhem. Two pairs of Proxmox systems are about to be joined by an additional trio. There is a complex n8n plant I’ve yet to examine closely. There’s an agent builder out there doing things I can barely comprehend with Vibe Kanban. Everybody installed Antigravity the minute it came out and there’s an orgy of retooling happening. Somehow this all has to distill down to a single “source of truth” Github, loosely under my control.
We are at the point where everyone is tired and the inevitable grousing begins - because each of us feels that they are doing more than anyone else. That is not true, but this always happens during startup launch, the question becomes does the group have the maturity to just grin and bear that feeling, without reacting over it.
Having drafted this in a burst of enthusiasm that began when I couldn’t sleep around 0400, I’m setting this to pst in the usual 7:57 time slot, and crawling back under the covers.
Pooling those RTX cards together would definately be a game changer. Running distributed inferance across 96GB of separat cards is such a headache compared to having it all unified. The 6000 Pro would simplify everythng.